

Microsoft Fabric Preview Projects: There’s a Different Fabric for Each Use Case, and That’s a Good Thing
Since Microsoft Fabric was released in public preview earlier this year, iLink has worked with our customers to develop end-to-end analytics projects using the new platform. We have had the opportunity to put the claims of an all-in-one enterprise-scale software as a service (SaaS) analytics platform to the test, and in this post, we’ll share what we’ve learned, what we’re excited about, and our overall impression.
What is Microsoft Fabric?
Microsoft Fabric is a single SaaS platform that combines seven core analytics workloads into one product, simplifying and unifying governance, security, administration, billing, navigation, monitoring, etc. It includes data engineering, data warehousing, data science, real-time analytics, Power BI, and a new tool to automate actions from data called Data Activator. The cherry on top of this multi-layered platform is Copilot, which promises to simplify the creation of Power BI reports, more easily provide insights, support the development of code, and more.
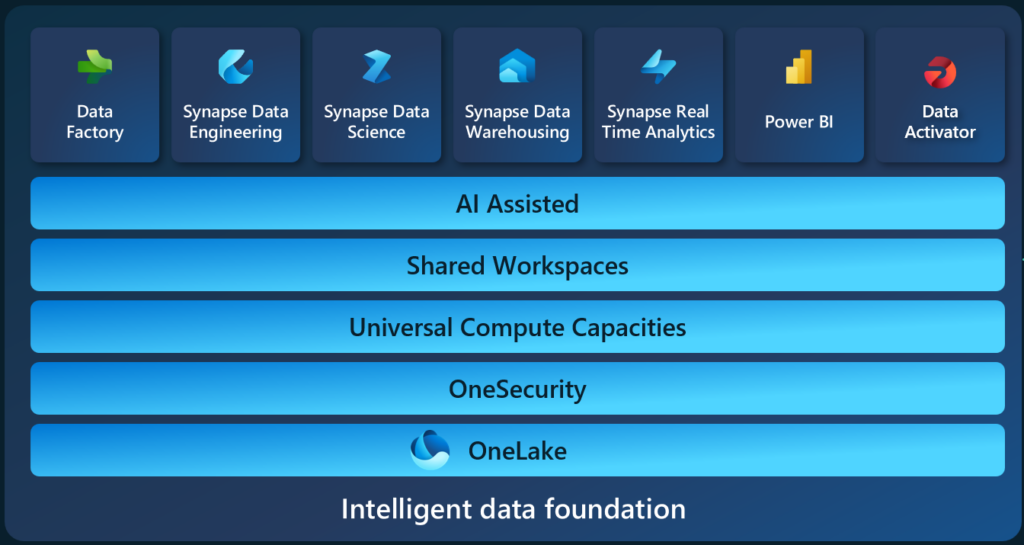
What new tools and features does Fabric offer?
Fabric takes many of the analytics products previously offered by Microsoft and brings them all together under one roof. These include Power BI, Azure Data Factory, Synapse Analytics, etc. However, Fabric is more than just a combination and rebranding of existing tools. A few of the new tools and features that are part of the service include:
- OneLake: OneLake (the OneDrive for data) is the storage layer and the foundation for all of the workloads in Fabric. OneLake is a multi-cloud data lake that is automatically provisioned for an entire tenant. Delta, the storage format for Fabric workloads is open, meaning that other tools beyond Fabric can easily access and work with data stored in the OneLake. Additionally, to reduce duplication of data, OneLake provides two key capabilities: shortcuts and mirroring. Shortcuts allow seamless connections between OneLake and external storage. Mirroring (in preview) provides near real time data duplication from other cloud data warehouses to Fabric, without needed to build pipelines. Finally, all of the Fabric workloads have been optimized to store and retrieve data quickly in the delta format, including Power BI.
- Direct Lake mode for Power BI datasets: In addition to import mode and DirectQuery mode for Power BI datasets, Fabric brings us the best of both worlds with Direct Lake mode. Direct Lake mode gives us the real-time capability of DirectQuery but with the speed of import. This can be a huge relief in those cases where import mode dataset refreshes become challenging, for example.
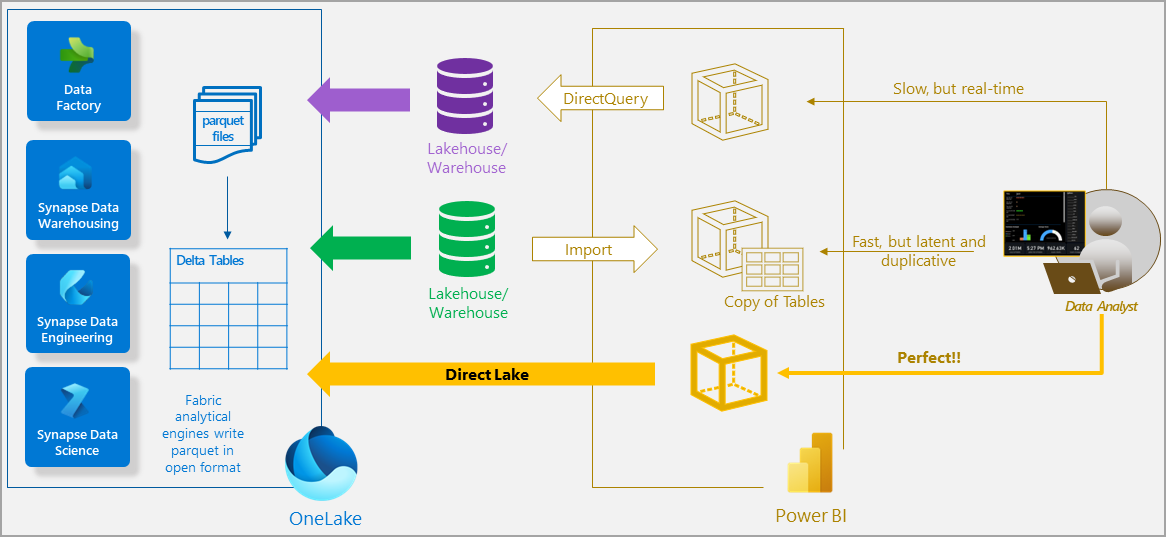
- Data warehouses and lakehouses: Storing data in a Fabric data warehouse and/or lakehouse within the familiar environment of Power BI allows both data engineering experts and non-experts to meet their data storage, transformation, and access needs in one place, without the need for complex set-up or configuration. It also provides many more methods and tools to access data used for Power BI reports beyond DAX and visualization tools. For example, when data is stored in a lakehouse and Power BI uses Direct Lake mode to access the data, other personas can choose to query it with T-SQL via the SQL endpoint or with Python via a Spark notebook.
- Single compute model for all workloads: With Fabric, you purchase a certain level of compute and all of the workloads come from the same pool. This simplifies planning for workloads and billing. Instead of creating different subscriptions and groups for each workload, you simply purchase an F SKU (stock keeping unit), and all the workloads draw from that compute. With the Fabric Capacity Metrics app, it’s possible to see how much of your compute is being used by each workload over time and modify accordingly. With both a pay-as-you-go model and a reserved instance pricing model, this has the potential to simplify monitoring and save money.
- Spark notebooks: Notebooks open all kinds of possibilities, from data engineering to data analytics and data science. Spark compute is incredibly fast and increasingly used for many workloads. Being able to combine notebooks with orchestration through data factory pipelines is one of many ways to bring in and transform data to OneLake.
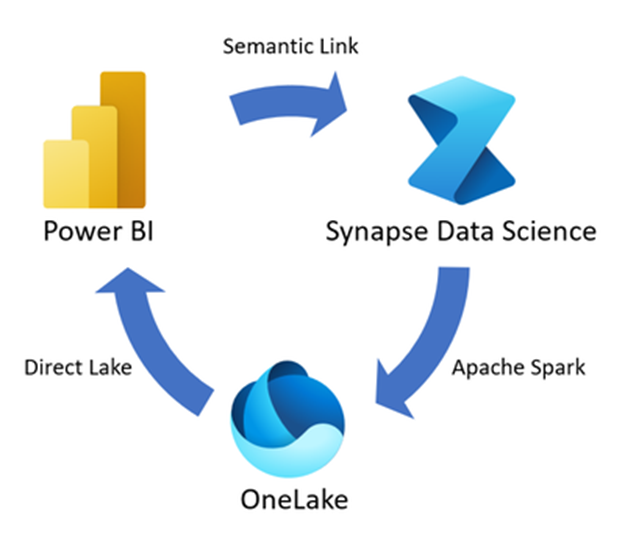
- Semantic Link: Semantic link is a new feature that gives us a way to establish a connection between Power BI datasets and data science using Fabric notebooks. This opens many possibilities including documentation and governance scenarios through querying which datasets exist in a tenant, development of machine learning models using Power BI data, and data quality validation through querying of both Power BI datasets and source data within a single tool.
What doesn’t change?
Because all of the non-Power BI workloads were brought into the interface of Power BI, Power BI users have the home-court advantage of a familiar working environment. Power BI itself still functions as before, but now has many added features such as DirectLake mode. Fabric just brings new features, tools, and licensing options to the game.
Lessons learned during the public preview
From iLink’s implementations of Fabric with our customers and through our own internal tinkering, we’ve had the opportunity to kick the tires and get a look under the hood. We’re happy to share some of the things we’ve learned, including:
- DirectLake mode really is a game-changer for Power BI datasets. By being able to query billions of rows of data and get nearly instantaneous results without needing an imported dataset refresh, our customers gain simplicity at a massive scale. In cases where we might have needed to build out complicated incremental refresh policies, custom partitions, or aggregate tables in the past, DirectLake mode instead allows us to directly access the data we need.
Lessons learned:- It’s also still very important to follow data modeling best practices to ensure optimal performance.
- There are row limits in DirectLake datasets where the dataset will fall back to DirectQuery if they are passed. When these limits are published, it will be important to pay attention
- Different workloads, particularly within engineering, have different levels of performance. For example, data transformation through Spark notebooks performs much better than through Dataflows Gen2 currently.
Lessons learned:- With Fabric there is often more than one way to accomplish a goal. It’s important to test out various methods to determine which one is the right fit for your scenario based on factors such as cost, performance, and team skills.
- With the release of a greater range of skus available, there is a much more affordable entry point to get started with Fabric. The lowest price for an F SKU is $263 (in US West)/month in a pay-as-you-go scenario. With reserved instance pricing this will be even lower. Compared to the lowest Power BI Premium capacity of a P1 at $4,995/month, this opens Power BI premium and Fabric features to a much broader range of organizations.
Lessons learned:- It’s critical to monitor your workloads with the capacity metrics app to ensure that you’re using the right capacity or capacities.
- A well-thought-out workspace and capacity strategy is a must if cost is important.
Conclusion
In working with Fabric for the past year, both while it was in private and public preview, iLink has had the opportunity to work with customers and the Fabric product team directly. Our successful implementations with both larger (Fortune 500) and smaller organizations has allowed iLink to become a Microsoft Fabric Featured Partner. This has given us a unique perspective on the product.
From our experiences and conversations, we see great potential for Microsoft Fabric, both for new and existing customers. Microsoft understands that many customers have already implemented large-scale analytics projects and have an existing foundation to work with. We have seen that Fabric plays well with others in scenarios like this, but that it also has all the components to support an end-to-end analytics solution at a massive scale. What this means is that Fabric doesn’t require you to fit into a specific use case for it to work for you. Instead, all the Fabric building blocks can be put together to fit your unique needs.
Fabric has the potential to increase developer and analyst productivity while reducing overall costs of ownership. On top of that, the introduction of Copilot within the various workloads of Fabric has the potential to be a true game changer. The 2023 “Total Economic Impact of Microsoft Fabric” Forrester report concludes that Microsoft Fabric will help increase productivity and reduce spend (by making it an end-to-end platform), leading to overall TCO reduction and much higher ROI. From what we’ve seen so far, we agree with their assessment.
We’re excited to continue working with customers on Fabric implementations and feel confident that Fabric is going in the right direction.
Contact us today to learn more about Microsoft Fabric and what it can do in your unique analytics scenarios.

Stephanie Bruno
Business Intelligence Architect

Top Technology Trends in Automotive Industry
Technological innovations like AI, autonomous vehicles, and AR are revolutionizing the automotive in...

Telecom Industry Trends: Shaping the Future in 2024
Explore the top 5 telecom trends for 2024: 5G expansion, network virtualization, edge computing, cyb...

6 Benefits of Adopting Low-Code No-Code Platforms for Businesses
Unlock business potential with low-code/no-code platforms: fast development, cost savings, accessibi...

Revolutionizing Industries with Power Platform: Case Studies and Insights
Explore transformative technologies like AI, Quantum Computing, and Industry Cloud Platforms, set to...

Top 6 Emerging Technologies in 2024: A Glimpse into the Future
Explore transformative technologies like AI, Quantum Computing, and Industry Cloud Platforms, set to...

Top Technology Trends of 2023: A Year in Review
Explore 2023's pivotal tech trends: Generative AI's impact, Blockchain's trust-building, Low/No Code...

How Top Industries can benefit most from Data Science & AI
Explore the revolutionary role of Data Science and AI in propelling industries forward. From reimagi...

6 Guided Strategies for Microsoft Power Platform Implementation
The Microsoft Power Platform offers organizations the ability to accelerate digital transformation w...

Choosing the Right Cybersecurity Services Partner: Step-by-Step Guide
In this blog, we'll guide you through the crucial process of selecting the perfect cybersecurity all...

The Value of Regular Security Audits: Safeguarding Your Digital Fortress
Imagine your company's digital infrastructure as a castle and its data as your most treasured posses...

Cybersecurity Awareness Training: Arm Your Team Against Digital Threats
While most organizations invest in state-of-the-art security solutions, there’s often an overlooked...

The Financial Impact of Cyber Breaches on Businesses: Direct & Hidden Expenses
Cyber breaches cost businesses millions, with both immediate and long-term financial impacts. Beyond...

How Technology can help to Bolster Employee Engagement and Happiness
Unlock employee happiness and engagement with technology. Discover strategies like flexible work, co...

Why is Beak the Ultimate AI-Based Solution for Your IT Infrastructure Challenges
Discover Beak - An Intelligent GPS for Infrastructure Monitoring, SOC, NOC & RMM. Streamline ope...

Microsoft Fabric: Unleashing the Power of Next-generation Data Analytics with AI Capabilities
Explore Microsoft Fabric, the cutting-edge data analytics platform that combines AI capabilities wit...

Streamlining Your Migration from Crystal Reports to Power BI
iLink Digital specializes in seamless Crystal Reports to Power BI migration. Explore feature compari...

Streamline Your Business with ServiceNow Bonding: Simplifying Integrations
In today's interconnected business landscape, seamless data exchange between systems is crucial for...

A New Way of Building Attended Automations with UiPath Apps, UiPath Forms & Triggers, and FromIo
Building attended automation is crucial for businesses seeking operational efficiency and improved u...

Conversation AI Vs. Generative AI: Decoding the Difference
In this blog post, we delve into the unique realms of conversational AI and generative AI. We explor...

5 Tips to keep your Salesforce Org Health in Top Shape
As a business leader, it's crucial to prioritize the health of your Salesforce org to ensure optimal...

Ace your Qlik to Power BI Migration in 10 Steps
Are you planning to migrate from Qlik to Power BI? The process can be challenging, requiring careful...
Why Your Business Should Migrate from Cognos to Power BI?
Learn why businesses are choosing to migrate from Cognos to Power BI and how it can maximize the val...
![Aligning DevOps with AWS: Development Stage [Part 4 of 9]](https://www.ilink-digital.com/wp-content/uploads/2023/06/image-400x400.png)
Aligning DevOps with AWS: Development Stage [Part 4 of 9]
Discover the power of DevOps with AWS in the Development stage! Leverage services like AWS Cloud9, C...

Modernization to Elevate IT Resilience: Answering Why & How?
Discover how modernizing your systems can significantly improve your business's IT resilience. In to...

Chatbots for Customer Service: A Must in 2023?
Driven by artificial intelligence, chatbots are shaping the future of customer service with their tr...

5 Strategies for Maximizing Business Value on Your Cloud Journey
In today’s digital era, harnessing the power of the cloud has become an indispensable element for bu...

Maximizing Revenue and Driving Growth with Salesforce Revenue Intelligence
In today's data-driven business landscape, maximizing revenue and driving growth is crucial for comp...

Why Power BI is a Game-Changer for Your Business Intelligence Needs
Power BI is a powerful business intelligence tool that enables organizations to make data-driven dec...

MULTI-TENANCY ON OUTSYSTEMS: Answering How & Why?
OutSystems is a low-code platform that offers multi-tenancy support, a critical feature for modern a...

Greening the Cloud: How Cloud Computing Can Help the Environment?
Cloud migrations have the potential to reduce energy consumption by 65% and carbon emissions by 84%...

Conversational AI in Insurance Industry: Top Use Cases to Explore
Looking to explore the potential of Conversational AI in the insurance industry? Our in-depth blog p...

5 Ways Companies can lower their Carbon Footprint and Contribute to a Greener Future
As we navigate through the climate crisis, the need for businesses to prioritize carbon management h...

Mastering Salesforce Queues: A Comprehensive Guide to Boosting Your Productivity
As a sales professional, you're always looking for ways to streamline your work and be more producti...

6 Technologies to help your Business Achieve Sustainability Goals in 2023
Many corporate leaders are also discovering that sustainability can deepen their organization’s sens...

How IoT is reinventing Manufacturing and Supply Chains Industries in 2023?
IoT has transformed manufacturing operations and supply chain management by increasing operational s...

The Future of IoT: Trends and Predictions for 2023
The Internet of Things (IoT) has come a long way since its inception over a decade ago.
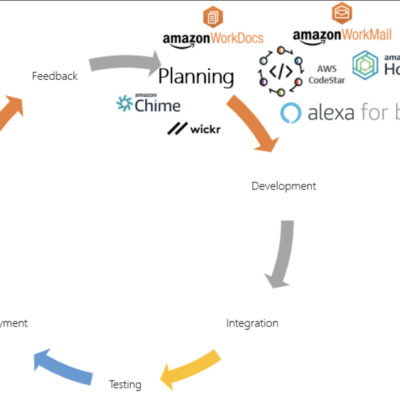
Aligning DevOps with AWS: Planning Stage [Part 3 of 9]
In this article, 3rd in the series, we will discuss the Planning stage of DevOps using AWS and intro...

Cloud-Based RPA: The Next Frontier in Automation
Automation has become a buzzword in the business world, and for a good reason. Companies are embraci...
How can Businesses use ChatGPT to upgrade their Customer Services?
Businesses can leverage ChatGPT to take their clients’ experience to the next level. For example, re...
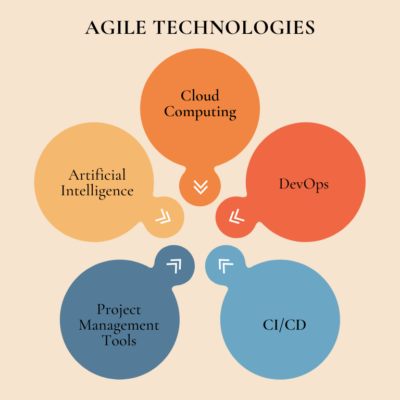
Agile Technologies: Revolutionizing Business Efficiency and Innovation
Businesses that use agile technologies have gained insights, worked faster, and built stronger relat...

Top 7 Salesforce Trends To Follow in 2023
As one of the most powerful CRM platforms, Salesforce assists businesses to build customer databases...
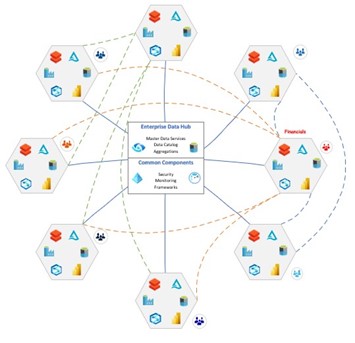
What is Data Mesh? | Architecture, Principles, and Benefits
What is Data Mesh? Data mesh is a decentralized data architecture that groups data according to a pa...

Understanding Data Fabric, its Key Components & Benefits.
Data fabric integrates and connects to your organization’s data while removing the complexities invo...

What is IoT Analytics and Why Business Leaders should care?
48% of companies use IoT in their business. Imagine the amount of customer data being collected. Wit...
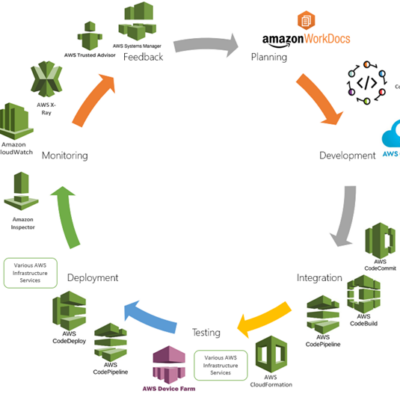
Aligning Services with DevOps Stages [DevOps with AWS – Part 2 of 9]
One popular platform for implementing DevOps practices is Amazon Web Services (AWS). In this article...

9 Best Practices for Protecting Data Privacy in 2023 and Why they shouldn’t be disregarded.
The average cost of a data breach is currently $4.35 million, and that amount will only increase. Al...

iLink Digital Earns 2024 Great Place To Work Certification™ for the Second Consecutive Year for Outstanding Workplace Environment
Bothell, WA, – iLink Digital is proud to be Certified™ by Great Place To Work® for the 2nd yea...

Embrace the Data-first Marketing with Marketing Cloud Intelligence
Marketers empowered by accurate data can personalize messages and services to align with customer pr...

Why Does Your Business Need to Take An AI-Driven IT Security Assessment?
Cyber threats are becoming more sophisticated and pervasive than ever before. The cost of cybercrime...
