Advancing Data Science with Language Models: LLMs and their Impact
Data Science & AI
Advancing Data Science with Language Models: LLMs and their Impact
Large Language Models (LLMs) have ushered in a new era of data science, igniting a transformative impact on the way we process and generate text. As we continue to refine and integrate these models, they hold the key to bridging the gap between language and other data domains, paving the way for groundbreaking advancements in data science.
Large Language Models (LLMs) have exploded into our consciousness over the past several months due to the incredible success of GPT-based models. In fact, Microsoft claimed that chatGPT was the fastest-growing consumer product in the history of the web. The success of these models has started a mad race towards incorporating these models in all aspects of technology.
Companies, cutting across industry segments, are looking to understand how to use these models to boost their businesses. But, before we look at the impact that LLMs can have on our lives, it would be instructive to take a short walk through the history and the development of these models.
A Brief History of Large Language Models (LLMs) Evolution
Humans have always been fascinated by technologies that would enable machines to understand, generate, and interact with human language. From rule-based approaches to statistical models and deep learning techniques, the field of Natural Language Processing (NLP) has witnessed significant advancements. The emergence of Large Language Models (LLMs), led by the transformer architecture, has revolutionized data science and text processing.
To gain a comprehensive understanding of their journey, let’s explore the following timeline.
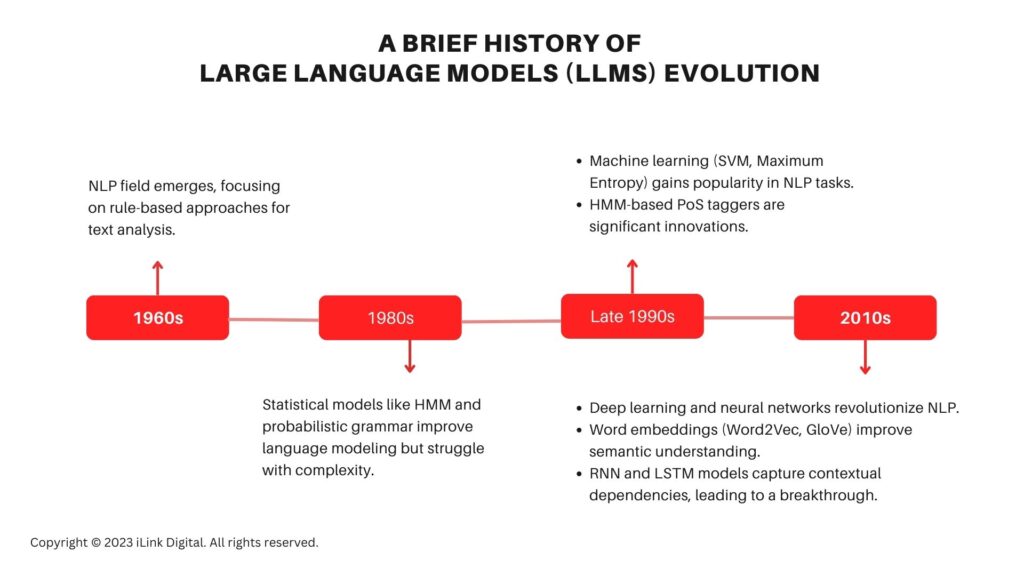
1960s: The field of Natural Language Processing (NLP) emerged with researchers initially focusing on rule-based approaches where linguistic rules were manually encoded to process and analyze text.
1980s: The following decades saw the growth of statistical models using techniques like Hidden Markov Models (HMM) and probabilistic, context-free grammar to model language. These models while an improvement on the rules-based approaches, still suffered from an inability to handle the complexity and ambiguity of natural language.
Late 1990s: This decade marked a shift towards machine learning approaches in NLP. Researchers started using techniques like Support Vector Machines (SVM) and Maximum Entropy models to tackle various NLP tasks such as text classification, named entity recognition, and information extraction. These models leveraged large annotated datasets to learn patterns and make predictions. In addition, HMM-based parts-of-speech (PoS) taggers were a significant innovation during these years.
![]()
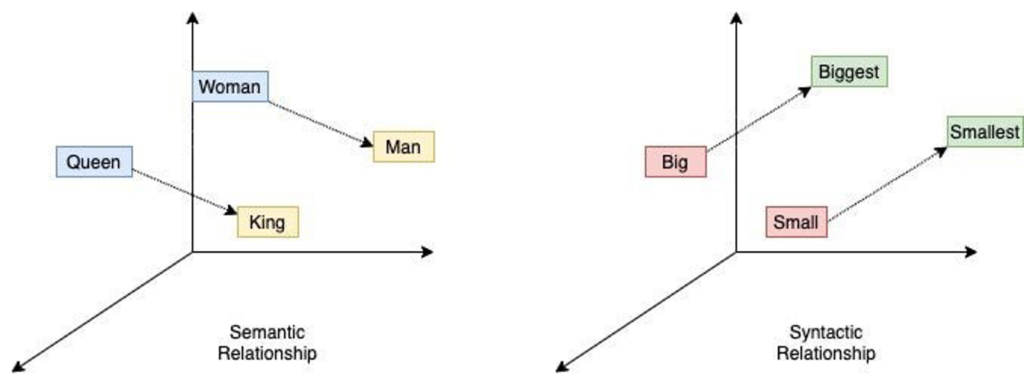
2010s: The paradigm shift in NLP occurred with the emergence of deep learning and large-scale neural networks. The availability of large datasets and compute farms coupled with advancements in hardware accelerated the adoption of deep learning models. Word embeddings like Word2Vec and GloVe provided dense vector representations of words, enabling better semantic understanding.
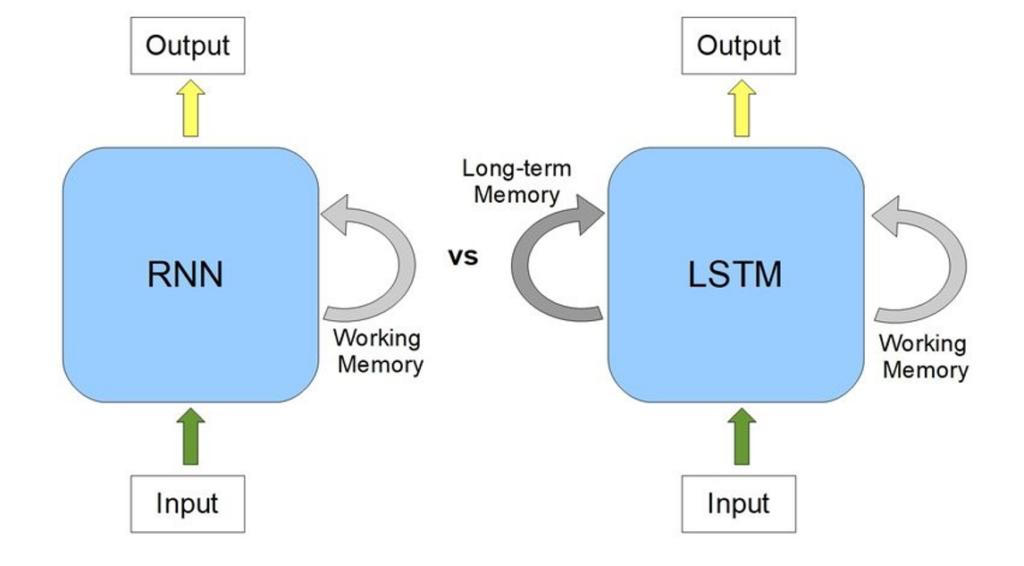
The real breakthrough came about through Recurrent Neural Networks (RNN) and Long Short-Term Memory (LSTM) models which were capable of capturing contextual dependencies in the text.

The Rise of Large Language Models (LLMs)
In recent years, a new breed of language models known as Large Language Models (LLMs) has emerged, spearheaded by the Transformer architecture. These LLMs have revolutionized the field of data science and are transforming the way we process and generate text. Generative
Pre-trained Transformer (GPT) based models are pre-trained on vast amounts of data and have hundreds of billions of parameters. For example, GPT3.5 was trained on a corpus of diverse text from the internet, encompassing a wide range of topics and writing styles. This extensive training data enables the model to learn intricate patterns, semantic relationships, and contextual nuances present in human language.
While in the past, models would be trained for specific tasks, these GPT models can take on new tasks without being trained specifically for them, in a method now known as no-shot learning.
One of the most notable achievements of LLMs is their ability to generate coherent and contextually relevant text. These models can generate high-quality prose, news articles, poetry, and even code snippets with remarkable fluency and creativity. They have pushed the boundaries of what was previously deemed possible in automated text generation. The output from LLMs is often indistinguishable from human-written text, which has vast implications across various domains such as content creation, chatbots, virtual assistants, and more.
Beyond Just Text Generation: Diverse Applications of Large Language Models (LLMs)
The impact of LLMs goes beyond just text generation. These models have proven to be incredibly useful in a wide range of tasks such as language translation, sentiment analysis, named entity recognition, question-answering, summarization, and more. LLMs have achieved state-of-the-art results in benchmark datasets, surpassing previous approaches by a significant margin. This progress has the potential to revolutionize industries that heavily rely on language processing, such as customer support, legal research, market analysis, and information retrieval.
Interestingly, LLMs are also starting to be used for tasks such as generating images and videos from textual prompts. What is even more surprising is that these models are now being used to generate code in multiple programming languages.
LLMs have also played a vital role in democratizing access to advanced NLP capabilities. Previously, developing high-performing language models required substantial computational resources and expertise.
However, pre-trained LLMs can be fine-tuned on domain-specific data, allowing organizations and researchers to build powerful language models without starting from scratch and bringing down costs substantially.
This has lowered the entry barriers for NLP development and paved the way for innovation in a wide range of applications across the globe. A plethora of startups are now working on incorporating these models into new technologies.
Researchers are also actively investigating techniques to enhance the interpretability and controllability of these models. A recent paper talked about the similarities in the Electro Encephelograph (EEG) signals from a human brain and the neuronal activations from a deep neural network for the same task.
By understanding and visualizing the internal mechanisms of LLMs, we can gain insights into their decision-making processes and biases. This knowledge can help address concerns about ethical considerations and ensure the responsible deployment of language models in real-world applications.
Future Advancements and Potential of Large Language Models (LLMs) in Data Science
LLMs hold immense potential for future advancements in data science. Continued research and development will refine the training methodologies, architectures, and fine-tuning techniques, leading to even more powerful language models. Furthermore, integrating LLMs with other fields such as computer vision and reinforcement learning could enable machines to comprehend and generate multimodal content, bridging the gap between language and other forms of data.
In conclusion, Large Language Models are starting to revolutionize the field of data science, particularly in the realm of natural language processing. Their remarkable ability to generate coherent and contextually relevant text, coupled with their superior performance across various NLP tasks, has opened up new possibilities in content creation, virtual assistants, customer support, and more.
Interested in Harnessing the Power of Language Models (LLMs) to Advance Data Science?
iLink Digital is a leading provider of generative AI solutions that help businesses like yours to leverage the full potential of LLMs, driving innovation and transforming your organization’s data-driven initiatives.
Explore our page to learn more about our cutting-edge solutions, deep expertise, and successful implementations in the field of LLMs. Our team of AI experts is dedicated to helping you unlock the transformative capabilities of LLMs, enabling you to gain valuable insights, enhance decision-making, and drive tangible business outcomes.

Arun Krishnan
Senior Vice President,
DATA BU
About Author
Arun is the Sr. VP and Practice head for Analytics and AI at iLink Digital with over 24 years of cross-geographical experience in academia and industry. His exceptional proficiency lies in implementing cutting-edge algorithms and solutions for data analysis and pattern recognition in the domains of Engineering, Information Technology, and Biotechnology. His extensive wealth of knowledge and experience, coupled with a robust publication record, positions Arun as a key driving force in pioneering innovation and achieving transformative results within the field of Analytics and AI.
SHARE
Share on facebook
Share on google
Share on twitter
Share on linkedin
Related Blog Posts

Advancing Data Science with Language Models: LLMs and their Impact
Data Science & AI Advancing Data Science with Language Models: LLMs and their Impact Large Lang…
Continue readingSHARE

iLink Digital Receives SOC 2 Type 2 Accreditation, Solidifying Its Commitment to Operational Excellence and Data Security
iLink Digital Receives SOC 2 Type 2 Accreditation, Solidifying Its Commitment to Operational Excelle…
Continue readingSHARE

5 Tips to keep your Salesforce Org Health in Top Shape
As a business leader, it’s crucial to prioritize the health of your Salesforce org to ensure optimal…
Continue readingSHARE








![Aligning DevOps with AWS: Development Stage [Part 4 of 9]](https://www.ilink-digital.com/wp-content/uploads/2023/06/image-940x640.png)