

Breaking Down Data Silos: How Microsoft Fabric and Databricks Create Cost-Efficient Hybrid Solutions
The data disconnect is costing enterprises millions. Here’s how to fix it without breaking the bank.
The Million-Dollar Data Problem
Picture this: Your VP of Sales sees an immediate $300K expansion opportunity with a 75% probability of closing. Meanwhile, your Customer Success team is watching the same client’s health score plummet from 85 to 65, with multiple open support tickets and declining user engagement.
This scenario represents “the data disconnect” – a costly reality where 68% of leaders agree that unifying their data platform is crucial, yet most companies continue operating with fragmented, siloed systems that create blind spots and missed opportunities.
The stakes are significant: Research shows that even a 10% boost in data usability can generate over $2 billion in additional annual revenue for the average Fortune 1000 company.
The Root Cause: Organically Evolved Data Estates
Most organizations have developed an “organically evolved data estate” – a complex web of disconnected systems that creates three fundamental problems:
1. Data Copies and Infrastructure Inefficiencies
Teams maintain multiple copies of the same data across different platforms, increasing costs and reducing accuracy. When sales and customer success work from different versions of truth, decision-making becomes guesswork.
2. Limited Interoperability
Manual data transfers, custom integrations, and middleware solutions are expensive to develop and maintain. They create bottlenecks that slow business operations and limit agility.
3. Data Exposure Risks
Fragmented systems increase security vulnerabilities and make compliance challenging. With data scattered across platforms, consistent governance becomes nearly impossible.
The Modern Solution: Hybrid Data Architecture
The answer isn’t choosing between platforms – it’s making them work together more efficiently. A hybrid approach combining Microsoft Fabric and Azure Databricks can eliminate data duplication while maximizing each platform’s strengths.
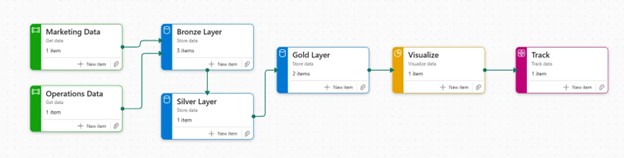
Figure 1: Microsoft Fabric pipeline showing unified data flow from Marketing Data and Operations Data through Bronze, Silver, and Gold layers to visualization and tracking
As demonstrated in our recent implementation, the pipeline seamlessly integrates multiple data sources:
- Marketing Data flows directly into the bronze layer
- Operations Data connects via shortcuts (avoiding duplication)
- Medallion architecture ensures data quality through Bronze → Silver → Gold progression
- Direct Lake provides near real-time Power BI performance
Three Trending Data Architecture Patterns
Modern organizations are implementing three complementary approaches:
- Data Mesh: Domain-driven autonomy allowing business units to operate independently
- Data Fabric: Automated data management and integration across disparate sources
- Data Hub: Open, governed Lakehouse foundation for unified storage
The key insight: These aren’t mutually exclusive. The most successful implementations combine elements of all three.
OneLake: The Unified Foundation
At the heart of this solution is Microsoft Fabric’s OneLake – essentially “OneDrive for data.” This provides:
Unified Data Lake
Organize data for central discovery, sharing, governance, and compliance across your entire organization.
One Copy of Data
Share data between users and applications using shortcuts without moving or duplicating data.
Trusted Data Hub
Access to a searchable hub where you can discover, manage, and reuse data all in one place.
Two Powerful Integration Methods
Shortcuts: Virtual Data Connection
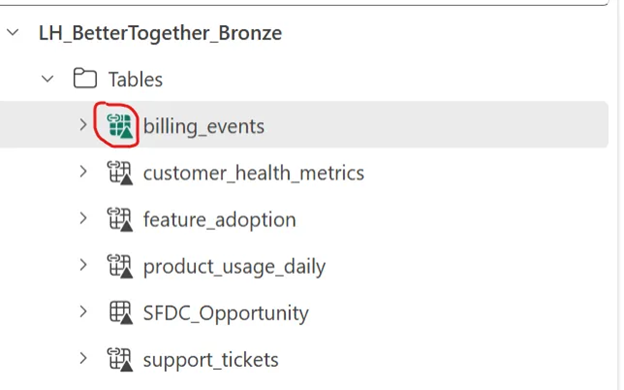
Figure 2: Fabric Lakehouse showing shortcut icons indicating virtual connections to external data sources
The screenshot above shows how shortcuts appear in Microsoft Fabric’s lakehouse interface. Notice the small shortcut icons next to table names like billing_events, customer_health_metrics, and support_tickets – these indicate data that physically resides elsewhere (in this case, Databricks pointing to ADLS Gen 2) but appears native to Fabric users.
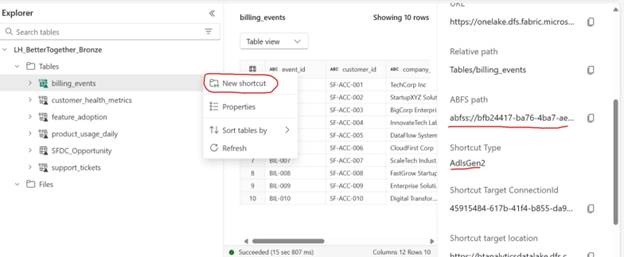
Figure 3: Shortcut properties showing the actual storage location and connection details
When you examine a shortcut’s properties, you can see:
- ABFS path: The actual Azure Data Lake Storage location
- Shortcut Type: AdlsGen2 indicating the source system
- Connection details: Direct pointer to the underlying data
Create virtual pointers to data without physical data movement. Like desktop shortcuts, these make external data appear native to Fabric while maintaining the source location. Perfect for:
- Large datasets in different clouds (Azure, AWS S3, Google Cloud)
- Existing Databricks lakehouses
- Any scenario where data movement isn’t desired
Mirroring: Near Real-Time Synchronization
Create synchronized copies of operational databases in OneLake with minimal latency. Ideal for:
- SQL databases requiring analytics access
- Systems that shouldn’t be directly queried
- Scenarios requiring consistent performance
Real-Time Business Intelligence: Data Activator in Action
One of the most powerful features demonstrated in our webinar was Microsoft Fabric’s Data Activator – the ability to create intelligent, automated responses to changing business conditions.
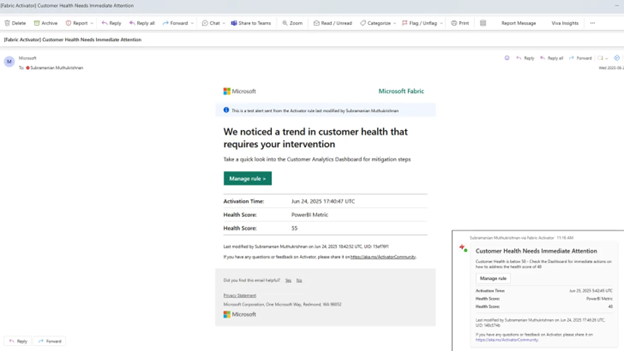
Figure 4: Automated email alert triggered when customer health score drops below threshold
The screenshot shows a real Data Activator alert in action:
- Trigger: Customer health score dropped to 55 (below the configured threshold)
- Automated Response: Email notification sent to customer success team
- Business Context: “We noticed a trend in customer health that requires your intervention”
- Action Button: Direct link to customer analytics dashboard
This transforms reactive customer management into proactive intervention, enabling teams to address issues before they become churn risks.
The Technical Architecture in Action
Here’s how the integration works practically:
Step 1: Unified Storage Foundation
All data is stored in open Delta-Parquet format, ensuring compatibility across engines. Whether data originates in Databricks, Fabric, or external sources, it’s accessible by all compute engines without import/export.
Step 2: Strategic Data Placement
- Bronze/Silver layers can remain in Databricks for complex transformations
- Gold layer in Fabric for business consumption
- Shortcuts connect layers without data duplication
Step 3: Enhanced Analytics
- Direct Lake mode provides blazing-fast query performance
- Universal security model enforced across all engines
- Shared APIs enable easy application integration
Business Value Demonstration
Consider Better Together Corporation’s transformation:
Before Integration: Sales pushed for deal closure while the customer was actually at risk and unhappy – a recipe for churn.
After Integration: Sales addresses customer issues first, then pursues expansion.
Result: Satisfied customers and successful sales.
This shift from siloed to unified decision-making delivered measurable improvements: 97% forecast accuracy (up from 76%), 4% churn rate (down from 12%), and 30% larger average deals.
We’ve helped similar transformations across industries – from commercial real estate platforms achieving near real-time analytics to Fortune 500 healthcare companies reducing report load times from 30 minutes to under 2 minutes.
Implementation Strategy
Modern Data Modernization Approach
Replace fragmented, compartmentalized environments with unified analytics platforms that connect to all on-premises, cloud-based, and third-party data sources.
Lakehouse Benefits
Adopt approaches that make it easier and more efficient to store massive amounts of different data types while reducing operational costs through lake-first strategies.
Rapid Deployment
Spin up analytics solutions quickly with minimal setup, deployment, and latency, enabling organizations to scale solutions and grow business faster.
The Seven Core Fabric Workloads
Microsoft Fabric provides integrated experiences across:
- Data Factory: 150+ connectors to cloud and on-premises sources
- Data Engineering: Spark authoring with live pools and collaboration
- Data Warehousing: Converged Lakehouse/warehouse with industry-leading SQL performance
- Data Science: End-to-end ML model development and collaboration
- Real-Time Intelligence: IoT and streaming data processing with automated actions
- Power BI: Industry-leading visualization and AI-driven analytics
- Partner Workloads: Extensible platform for specialized needs
Shortcuts vs. Mirroring: When to Use Which
Understanding when to use shortcuts versus mirroring is crucial for optimal implementation:
Use Shortcuts When:
- Data should remain in its original location
- You need to minimize storage costs
- Working with extremely large datasets
- Source system performance isn’t a concern
- You need cross-cloud connectivity (Azure ↔ AWS ↔ Google Cloud)
Use Mirroring When:
- You need consistent, reliable performance
- Source systems shouldn’t be directly queried
- Near real-time analytics are required
Getting Started: Practical Next Steps
Assessment Phase
- Evaluate current data architecture challenges
- Identify integration opportunities between existing Databricks, Snowflake and other data platforms
- Calculate ROI projections based on reduced duplication and faster insights
Pilot Implementation
- Choose a specific use case (like customer 360 analytics)
- Set up shortcuts between Databricks bronze/silver layers and Fabric gold layers
- Implement Direct Lake for improved Power BI performance
- Configure Data Activator for automated business alerts
Production Scaling
- Expand to additional data domains
- Implement comprehensive governance through Microsoft Purview
- Train teams on unified analytics workflows
- Measure and optimize performance continuously
The Transformation Imperative
This approach represents more than technical integration – it’s organizational transformation.
When teams work from unified data foundations, when finance gets reliable forecasts, and when data engineers focus on insights rather than integration overhead, entire businesses operate more effectively.
The companies succeeding in today’s data-driven economy aren’t necessarily those with the most data – they’re those who can act on unified, accurate insights fastest.
The bottom line: You don’t need to choose between Microsoft Fabric, Databricks, or Snowflake. By leveraging platforms through a unified foundation, right platforms for right personas, you eliminate data silos, reduce costs, and accelerate decision-making.
The question isn’t whether you can afford to implement a hybrid data strategy – it’s whether you can afford to continue operating with disconnected data systems.
Ready to unify your data estate? The path forward combines the analytical power of Databricks with the unified intelligence of Microsoft Fabric, creating a foundation for both current analytics needs and future AI initiatives.
Let’s connect over a free discovery workshop – Drop us a note, we look forward to our discussion.

Author
Subbu Muthukrishnan, Director at iLink Digital, brings deep expertise in solution engineering, data platforms, and real-time intelligence. He leads cross-functional teams of field engineers and solution architects to design transformative digital solutions that drive business growth. Passionate about helping enterprises modernize their data ecosystems, he has played a key role in shaping go-to-market strategies around Microsoft Fabric and cloud-native platforms. His forward-thinking approach makes him a key enabler of modern data platforms and intelligent decision-making systems.
